TLDR
This post deals with various problems in developing an streaming Android app. Don't be scared about the programming part, as we will deliver some boxes instead.
Motivation
I just replaced my Samsung S10 5G with a second-hand Pixel 7A at the beginning of this year. The reason was really straightforward, I wanted a smaller phone so that I could carry it around easier.
But that does not change the fact that the Samsung S10 is still functioning normally. Objects can feel heartbroken if not being helpful to human, you know. I don't want to let that much potential gather dust either. Let's breathe new life into it.
Why did I choose a streaming app?
Lately, my neighborhoods have started instailling surveillance cameras in their home. As far as I can remember, there hasn't been a single robbery of thief in my area, so I find installing one unnecessary. However, there's a thing called FOMO (Fear Of Missing Out), and a normal person like me cannot resist that feeling.
Combining these two reasons, our today topic is making an Android streaming app.
Objectives
Like always, I need to define the main objectives for the app first:
- Capturing video from camera and audio from microphone, obviously.
- I must have the ability to access and manipulate those data. Cause I want to run some processing algorithms in the future.
- Encoding the captured data. This sounds obvious to many of you, but I still note here in case somebody isn't aware of this. We shouldn't send the raw data over internet as it will eat up your bandwidth in no time. The most common approach is compressing (another word for encoding) these data.
- Client devices (PC/Android) can connect to the server device (old Android) and watch the live streams using any popular media player. Every live streaming method has its own standard and unique format. If I need a specific player to play them, that means they don't comply with those standards. This violation can lead to more issues in the future.
- The client and server devices don't need to be in the same local network. I intend to monitor my home from afar.
- No external server allowed. I don't want my data to be exposed to a third party.
- The resource utilisation is stable. It needs to be able to run for hours, or even all day. Even a small impact can "spark a big fire".
I had thought about being able to playback but soon ditched that idea. Serving those records might double the effort, whereas I actually don't need them at that moment. It should only be a nice-to-have feature, not a must-have, at least in the first version.
Available options
First, I want to check if there has been any adequate solutions before. Some apps run through my mind, but all of them comes with some downsides:
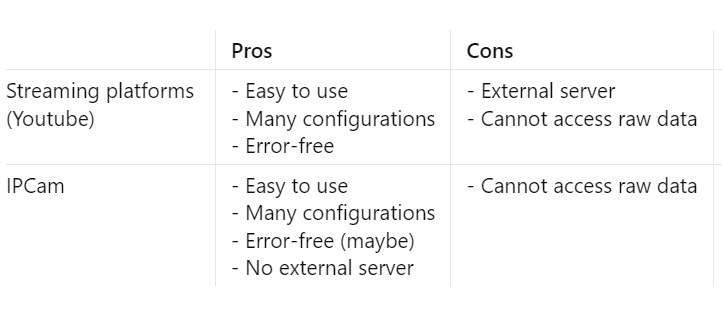
The most painful objective seems to be able to access the raw data. That leaves me no choice but to program an app myself.
Consider using IPCam on Google Play if you don't want to sink into the depressing hole of programming like me.
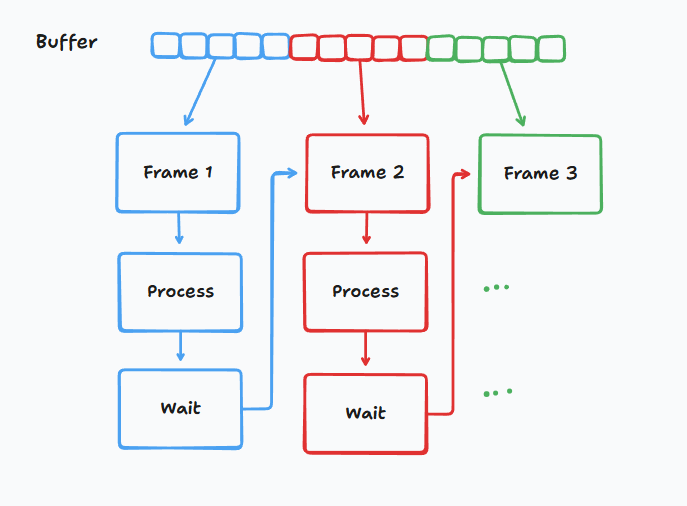
Pipeline
After breaking down every steps, I have the following chart:
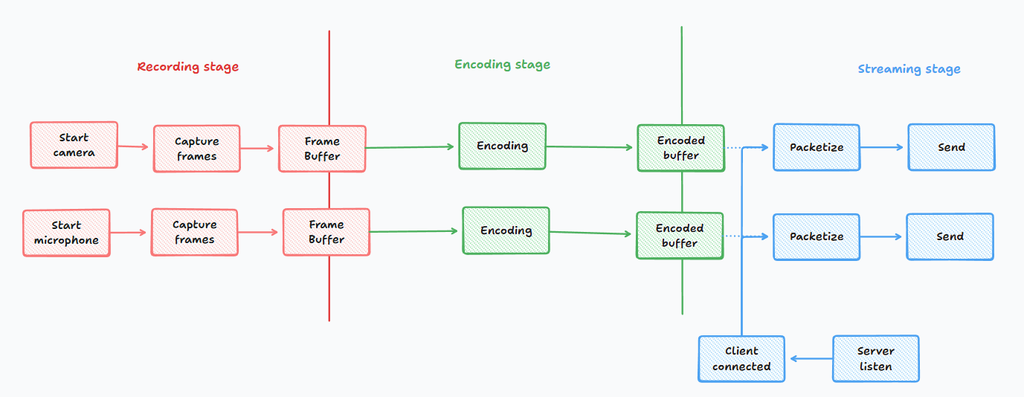
Why do I need those frame and encoded buffers? Is it easier to just pass the output directly to the next stage?
Take this as an example: Your friend are moving to a new house. You're helping him deliver some boxes from the 2nd floor to the ground floor. A common approach is that you take things from the 2nd floor to the 1st floor, and let your friend handle the rest.
Would you bring one box, wait for your friend to bring it to the destination and come back before you bring the next one?
The place you put down the boxes is called "buffer".
Moreover, by doing so, you can allow other people to help you and your friends. They just need to place or take the boxes from the assigned place. No waiting, at long as there're boxes to deliver. I'll discuss about this kind of waiting in the next section, it deserves a whole section to dive into the details.
With that logic in mind, every stage must run independently, they should only communicate through the buffers to transfer the data.
This also means each process should run on a dedicated thread. If you don't familiar with this term, it's simply asking a person to do something for you. One person can't multitask. If you want to do things in parallel, you need the same number of people.
Now that the big picture is clear, let's implement each piece in that picture.
Make it work first
From my experience, the first version should be made as fast as possible. It just needs to work, nothing else. Lagging, slowing and minor bugs are acceptable. This prevents you from over-optimizing everything at first.
The first problem appears quite soon. I don't know whether I'm so stupid that I can't grasp the Android API documentation, or they actually make it too fragmented and incomprehensible. Like I want to know how to start recording camera, they just throw me a bunch of code without explaining how each piece is connected with others.
Fortunately, I can ask ChatGPT how to code a specific step (for example, starting recording, capturing frames) then compare it with the documentation later. It's much faster this way.
Choosing the right encoder
Since there are a lot of encoding algorithm, we need to set some requirements to limit the candidates.
- It must use as least CPU as possible. As I might do some calculations along (object 2). Additionally, using more CPU means the phone get hotter easily, which makes it trigger thermal throttling => Impact the performance.
- Video quality is not much of my concern. As long as I can see things, it's acceptable.
Thus, I prefer those that have hardware acceleration. You can easy check what kind of codec your device supports (ask ChatGPT to write the code for you).
In my case, thay are H264, H265, VP8, VP9 for video and AAC, Opus for audio. It's worth noting that each encoder only utilizes hardward acceleration under specific configs. Make sure you set the right one.
If you are lazy, just pick whatever you want. But I need to use as least CPU as possible, so I will benchmark the utilisation for all of them.
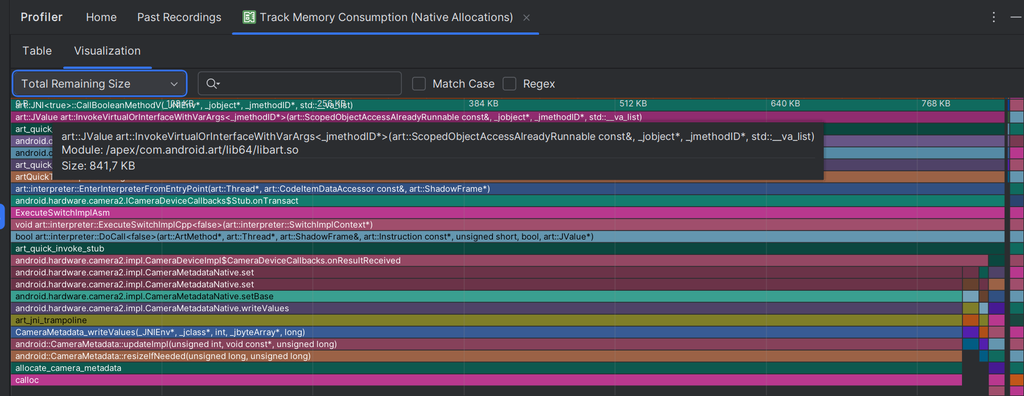
I ask ChatGPT to generate a demo app for me to record from camera and save output to a file. Then, I use the Profiler from Android Studio to monitor the CPU and RAM usage.
The result is as follows. We only need to focus the CPU and RAM columns.
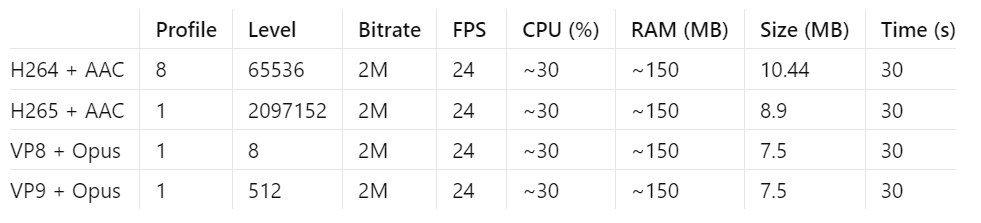
Wait, let me explain, it seems I'm so lazy that I simply copy the result from one experiment. But it actually oscillates around that point, I swear. These encoders show no differences regarding performance on my phone, which makes it more difficult to reach a conclusion.
How about comparing using the file size?
In reality, I don't store the file and just send all frames on the fly so that doesn't matter.
In the end, I choose H265 + AAC cause I like its name. No logical rationale here.
As for the packet standard, typical IP cameras use RTSP for streaming. I don't see any reason not to do that. After all, it just wraps the encoded data with a little bit more information, which has negligible effect to the CPU.
Buffer ordering
Now there's another requirement: your friend need to arrange them in a certain order. For example, he want to bring old boxes first, so that he can give away them more easily later.
You bring box A. Then you bring box B, which is more recent. But your friend hasn't pick box A yet. Where should you put the box B? In front of or behind box A?
Behind box A, right. Your friend can get box A more conveniently this way.
This is indeed my case here. I need the frame in chronological order, cause it's "live" streaming and we live as time moves forward, obviously. That's why we need to write the captured frames sequentially to the buffer. And the encoders/packetizers should read them in that order. In computer science, this data structure is called "a queue". You can search this term on Google (or ChatGPT) for more information or how to implement them.
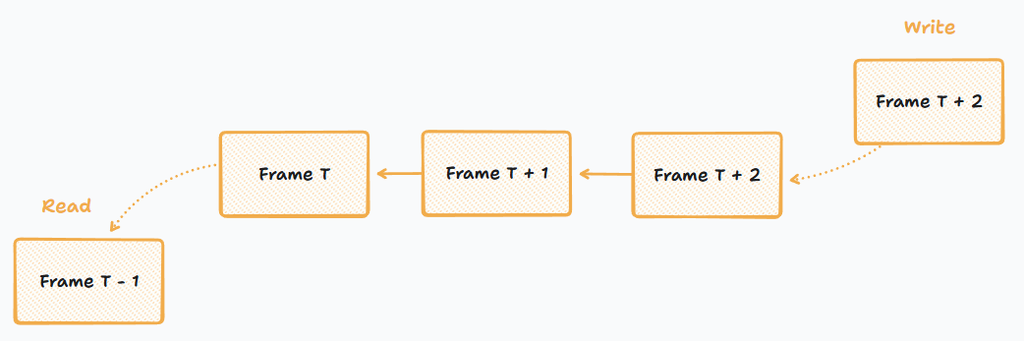
Should your friend wait there, or do something else and come back later?
Maybe your friend goes to the gym everyday, so he moves the boxes faster than you. While you're bringing a new box to the staircase, he's also standing there, staring at you awkwardly. Then his phones rang, he doesn't decide whether he should answer it or wait until everything is done.
Both approaches have their own pros and cons. If he waits there, he can deliver the next box as soon as possible, but he misses the chances to do anything else. If he picks up the phone, he can help someone else by responsing them in time, but he might come back a little later.
This situation is what the encoders and packetizers will face most of the time. Why?
Camera has an attribute called FPS, remember? That means it can only delivers N frames per second. If you process faster than that, most of the time is spent waiting.
In computer world, there are two types of waiting, which are equivalent to the two mentioned approaches. Busy waiting and blocking waiting. Busy waiting means the thread just stands there and does nothing else. You can easily deduce what blocking waiting means. Busy waiting costs so much CPU cycles that they are merely recommended except a very few niche cases.
You already know my priority. Blocking waiting is my answer.
However, it has a small discrepancy between blocking waiting and my analogy. For them to be the same, you need to tell your friend "I have brought a new one" for every box you deliver. This sounds troublesome, I know. But in computer world, it's much more efficient than busy waiting. CPU is the most important resource in our device, we must treasure every cycle of it.
I sent the packets, why don't the client recognize it?
Now I've had every pieces, let's connect them together. And voila...
It doesn't work. VLC and ffmpeg simply don't anything. They even say that nothing is received. But I can ensure from logging that I've sent the RTP packets sucessfully.
This is the most headache and hard-to-fix part. Because the error side (VLC/FFmpeg) is beyond our control, I can't open them to see which part causes the error. I only know that the format I sent has some problems. The question is, how to verify that?
Fortunately, there exists an application named Wireshard. It captures every packet from/to your computer and analyze them. You can easily validate all fields of a packet to see which field doesn't comply with the standard.
To be honest, Wireshark is my savior in this moment, I can't praise the dev team enough.
Thanks to Wireshark, now the packets finally can reach my laptop.
This's the end, right?
Sadly, nooooo. Another error message appears, which immediately ruins my joy.
"The audio frame came too early..." or something like that. Then, VLC disconnects the stream.
It seems the frames need to come at a fixed interval with small fluctuation.
Then... why are my audio frames sent so fast?
The continuity of the audio signal is the culprit. While the camera sends its frame at a consistent rate, the microphone just captures the environment sounds in real time, with no gap between them.
But the VLC complains that my frames are like fast-forwarded, that shouldn't happen if I just record in real time, right?
Yes, the culprit has an accomplice. That is the buffer I used to store the data.
To be specific, cause the audio is continuous, I'm always storing an amount of frames and processing them (encoding and sending) at once.
Remember the blocking wait. I can apply the same technique for this problem. I simply wait until the frame interval has passed then process the next frame. Fyi, one AAC frame contains 1024 samples, you can calculate the frame interval based on your sample rate. For example, if sample rate is 44100Hz, the frame interval is (1 / (44100 / 1024)) = 0.22 seconds. This option seems to have no downside.
Can't I just store one frame at a time (reduce the buffer size)?
This is another adequate solution. If the process is slower than the frame interval, a bigger buffer will contains more uninterrupted data than a smaller one. The gaps are still accumulated though. We shouldn't let this case happen anyway. The only downside I can see is that this solution heavily depends on the AAC encoder, so it will easily break if we change to another processor.
Too many grey frames
Finally, I can see the stream from VLC now.
This is a big milestone. Let's have a big party, yeahhhh.
...
However, the joy doesn't last that long. The stream is regularly interrupted by grey frames. If this only happens once in a while, I can stand it. But this frequency is way too high for an acceptable stream.
At first, I thought it was due to slow processor, then I logged all the captured and sent frames. Their numbers were the same, which meant I had sent all the captured frames successfully.
Wireshark, help me.
While all frames were sent from my phone, not all of them could reach my laptop. I checked the Wireshark log and noticed a huge gap in the frames received.

This can be explained by the transport method I'm using. The most common methods on the Internet are TCP and UDP. TCP ensures all packets are delivered, at the cost of higher latancy. Meanwhile, UDP can transmit frames with lower latency, but some of them may be dropped along the way. You should already know the answer by now, I'm using UDP, cause I can't resist the "lower latency" it offers. TCP simply uses the "receive and reply" technique to prevent data loss, not just "receive" like UDP.
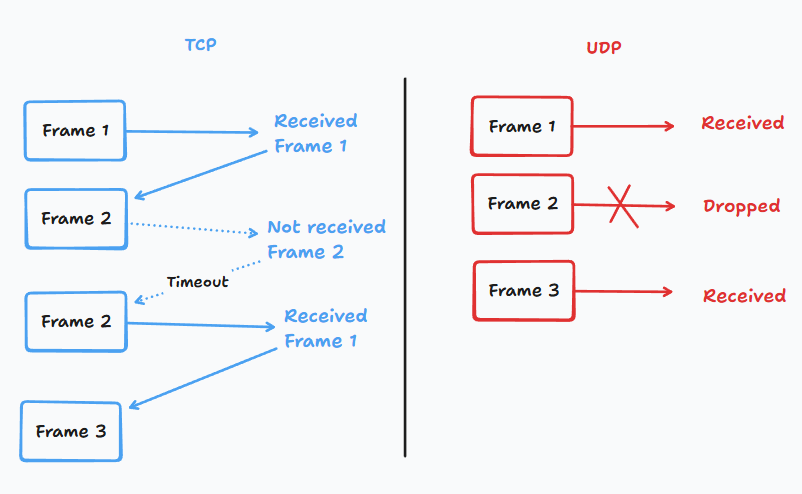
Wait a second, if the UDP drops some frames, why doesn't VLC just show the last frame instead?
That's the secret of all video encoders. They don't casually encode frame by frame, but do encode interframe. In real life, the transition between scenes is tiny, sometimes it's just some pixels moving in a large image. Video encoders only produce that difference instead of the whole frame. Once in a while, they encode a whole frame (I-frame or keyframe) followed by multiple transition frames (P-frame). When a keyframe is missed, VLC will show gray images for the P-frames instead.
After searching through Internet (this and this), I find that the most widespread solution is to switch to TCP, maybe the latency-consistency trade-off is not worth using UDP. Thanks to the similarity between the API, I can switch to TCP without hassle. Through some tests, I find the latency is still acceptable (~3-5 seconds). This number also does not accumulated over time, there is no reason to turn back to UDP now.
Can we reduce the latency even more?
Hey, I just said we should make it work first, why do I go straight to the optimization?
Technically, the app works now :v so I can do any optimization I want.
I can't resist when some ideas pop into my head.
In the last section, I mentioned that we can't reduce the buffer size between the recorders and encoders, because that would make recorders encoder-dependent, remember?
But we can do that to the buffers between the encoders and packetizers. They communicate through frame unit, not byte unit like the former case. Even if I change to another packetizer or processor, I always need only one frame at a time.
Why don't I reduce that buffer size to size 1?
This ensures the packetizers always process and send the latest frame, furtherly reduces the stream latency.
But, don't forget the keyframe missing cases. Like I explained in the last section, a P-frame always need a reference I-frame. Hence, if an I-frame is missed, I should deliver both the I-frame and the P-frame.
That makes the buffer have size 2. One for keyframes and one for P-frames.
Let's measure the performance
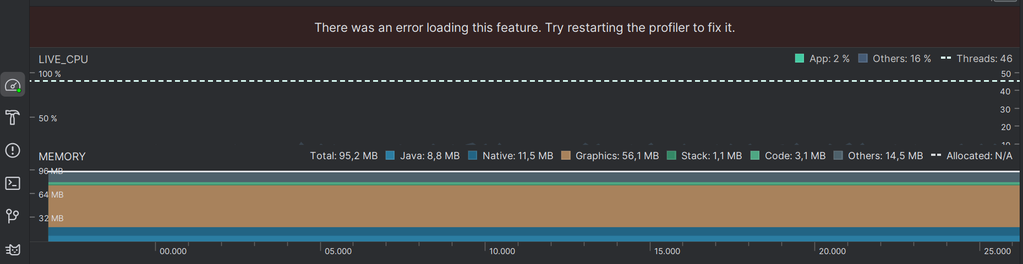
I already make it work. Now's the time to measure the performance to see whether I can improve anything (hope not).

CPU usage is adequate, it's even lower than the encoder benchmark, perhaps because I don't write to file this time.

The memory usage is not good though, garbage collector is triggered every 10 seconds. For those who don't know what is garbage collector is, just see it as the cleaner of your house. The more "garbage" (or memory) you use, the more often it has to work. This process is actually checking which memories are unused and "forgeting" them, so we can use that memory for other things later.
During the cleaning, you can't do anything, cause it can produce more "garbage". This heavily impacts the performance so I should avoid it at all costs. Also, this indetermined behavior may cause some unforeseeable affects.

The consequence is much clearer when I log some attributes. The number of dropped frames actually jumps up after a while. Note that these are the frames dropped in my pipeline due to slow processing (because I have set the buffer size to 1), which are not same as those dropped by UDP. As a result, the variance between the delta times of captured frames and sent frames skyrockets.
Why isn't the avg process time affected?
That number is just the packetizing time. I log it because that's the only part I might be able to improve. The encoding and capturing are already handled by the OS itself, thus I can't interfere much.
Dealing with memory spiking
Let's go back to the delivery example above. This time, your friend wanted to discard some old stuff. The building has a dedicated donation room for that purpose. Other residents or the landlord can adopt anything they find useful. Hence, he asks you to help him bring things from his room to that room.
Your friend also tells you that he has several obsolete big baskets in the room in case you need. How will you use those baskets?
Put some items into one basket, carry it to the destination, set out all items, then:
Bring the basket back to the room.
Or
Leave the basket there, go back to the room and use a new one.
Personally, I'll take option 1. Option 2 can run out of baskets so we must bring them back to your friend's room and reuse them anyway. This detour takes us some time and it's troublesome.
Wait a second, option 2 appears very similar to garbage collector, right?
You run out of memory/baskets, then you/the garbage collector free the unused ones to reuse them.
The take away is: reusing the memory as much as possible.
Unfortunately, the default languages for Android, which are Java/Kotlin, abstract so much the memory management from us. They can allocate unnecessary memory without our awareness.
As a result, I recommend switching to C/C++, an more low-level language, and avoid allocating dynamic memory as much as possible.
I proceed to convert the whole process to C, except the recording part, since that part is API call only. The final result really astonishes me. Not only the memory usage increase non-stop but also the garbage collect do not work anymore :). The only thing working as expected is that the increment happens very slowly.
I almost drop out of my chair this time.
Let's calm down and debug. I don't want my hours of refactor to go wasted.
The culprit seems to be related to the recorder API, according to this issue. More shockingly, the frequent running of garbage collector helps solve the problem.
Should I roll back now?
Another solution is to migrate to the C/C++ Recording API too.
I decide to take this path, since I don't want to accept that my work is meaningless.
After another few hours, finally, my effort has been paid off. I can't use enough words to describe this happiness. That feeling when I manually manage the memory is something Java/Kotlin cannot bring to me.
Waiting, waiting more, waiting forever
The delivery example above still has room to be exploited.
Consider this situation, you are going to drop a box to the assigned place (buffer), but your friend is also going to pick a box there. Should he wait for you then pick two boxes, or you wait for him then drop the box?
Why am I asking this, this is a trivial matter. Who cares about it? Anyone will do just fine.
Let me explain, what I am trying to emphasize here is the word "wait". Both options are someone waiting another, you notice?
What happen if none of us waits?
I know it's hard to imagine in the physical world. But thinking in digital view, your friend may pick a box that is half yours and half in the buffer.
Sound scary.
That phenomenon is called "race-condition" in computer science.
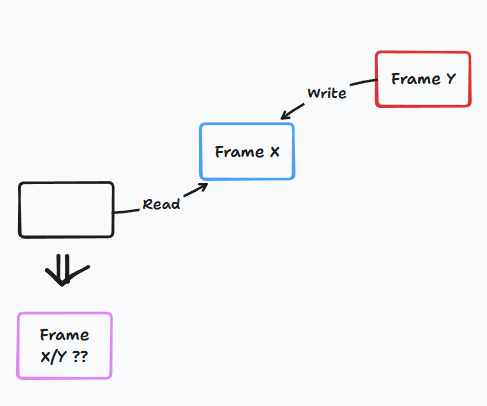
Wait, but I can just put the box there and my friend can pick 1 box only if the second box isn't "completed" yet, is that right?
You have notice the point. That why I don't mention this earlier, but postpone until now.
Because, now we have reused the buffer memory instead of creating a new one every time a box comes.
That "reuse" part is where the problem arises.
The solution is, once again, using blocking wait, just like in our physical world. Only one process can access that buffer at a time.
I don't want to wait him. Is there another solution?
Welcome to Computer Science,
Where there always exists a better solution.
I just exaggerate. Don't mind it.
In fact, there is no best solution, just how much trade-off we can accept.
In the last example, there's indeed a solution where you and your friend don't need to wait anything. This non-blocking behavior may be critical in some situations so I think I need to mention here, for example, the C++ Audio Recording API.
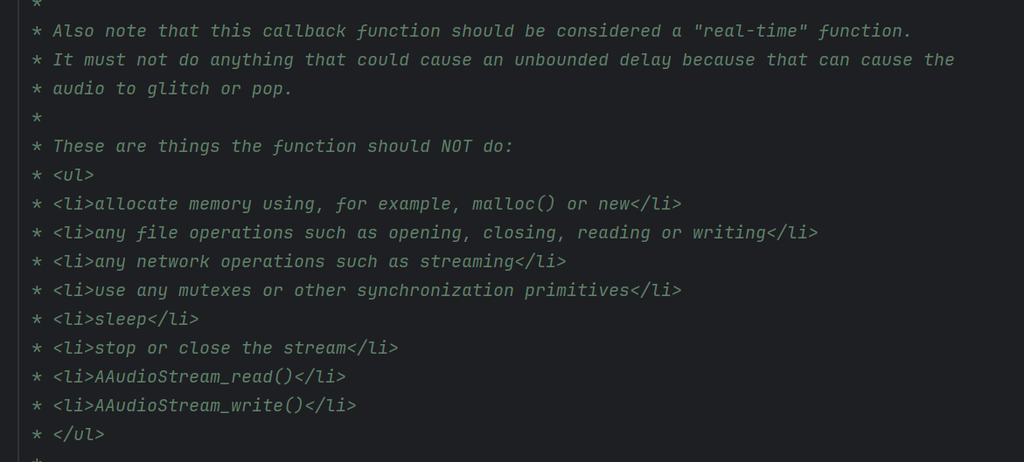
It sounds something terrible will happen if we wait in this function.
I don't want that to happen either, so let's find another way to avoid the race-condition.
The problem occurs because we are trying to read and write to the same buffer, right?
How about making them use different buffers this time?
One for read and one for write.
That's ridiculous, the read buffer is meaningless, cause the writer can never access it.
How about... switching them continuously?
That's.... Wait, it seems logical. If only we can find a way to switch them efficiently.
Why not, instead of switching them, we can simply ask the reader and writer to swap their buffer immediately.
Let me use the delivery example one last time.
Your friend doesn't want you to wait for him. So he designs 2 places with a flag. If he put the flag in one place, you just need to bring the boxes to that place, don't be concerned by anything else.
Your friend waits there. When he sees the marked places filled with enough boxes, he takes the flag off and put it in the other place.
This approach ensures you will never wait for your friend. Just mind your own business.
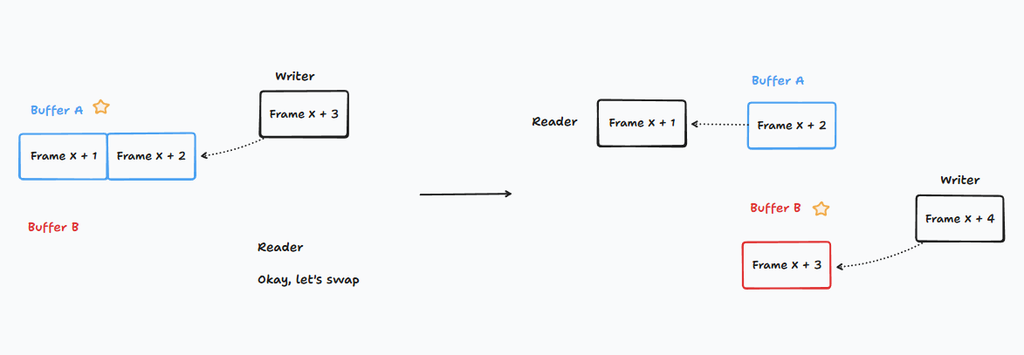
It seems too good to be true. There must be some downsides, right?
If you don't care about the labor exploitation, there are only two things to consider.
First, the complexity in the design. Second, you need double the buffer.
If none of them is your problem, which is true in my case, this method is worth trying.
In Computer Science, this technique is called "Double buffer". You can investigate more by searching this keyword.
This is the new log after all the refactoring and optimizations are applied. The stream is much more stable now. Hehe.

A little more optimization, should I do if nobody asks?
I won't use the delivery example anymore, I swear. This section is much shorter than you can ever imagine.
In case of streaming, if there is no client connected, we shouldn't encode any frames, right?
Last but not least, connection
Just use Tailscale.
I can't recommend that enough. There are so many mind-blowing techniques in this small application.
You can read more about how it works in this post.
Conclusion
This project had been nurtured for a long time. I only got the chance to bring it to life now. There were more issues than I had expected, it also took longer time to develop as I needed to learn many new things along the way. However, the knowledge gained and the results achieved are worth far more than that effort.
I hope I can convey these knowledge and enjoyment to you in an easy-to-understand way. For me, programming are just tools. That's why I prefer telling the core idea to providing the actual code.
You can find the full code in this link.
Thanks for reading.